
Selenium爬虫脚本使用举例(以百度为例)
该文章为脚本示例代码解释,具体代码及接口参数请参考666cy666/Selenium_Util: 本仓库为selenium脚本封装库,利用python装饰器以及闭包思想,致力于更好的调试自动化爬虫,让爬虫技术更好入门 (github.com)
初始化驱动和加载器
初次使用请在参数中加入 update=True更新驱动,该参数将自动匹配适合本机的selenium驱动
from Selenium_Util import Selenium_Edge
from selenium.webdriver.common.by import By
edge_driver = Selenium_Edge(update=True)
爬取相应文字和图片,这里我们以百度为例
# 打开相应网址
edge_driver.get_driver('https://www.baidu.com')
几种通过xpath找元素的形式
函数名中带element下标的皆为用装饰器装饰的函数,可只传入xpath,无element下标的函数与原selenium函数无异,需要先获取元素再将参数传入,具体请看如下示例
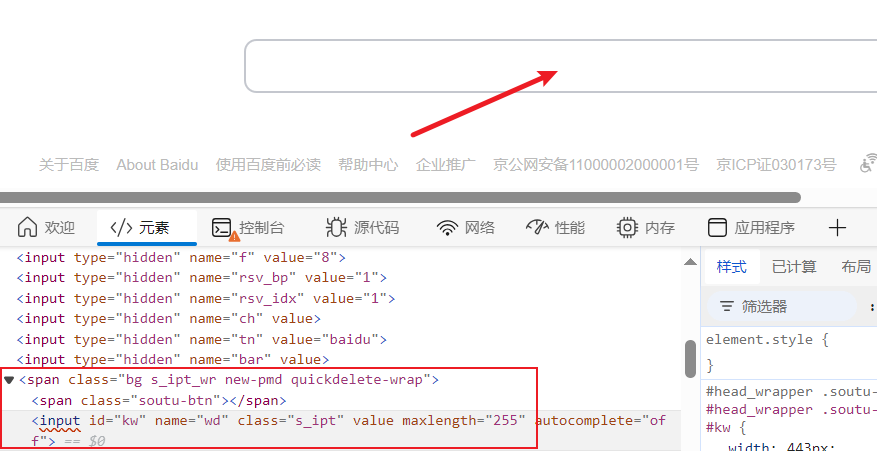
# 直接输入xpath
edge_driver.input_element_text('//*[@id="kw"]',text="selenium")
# 通过指定xpath_kind,这里以id为例
edge_driver.input_element_text(xpath_kind=By.ID, xpath='kw',text="ID")
# 通过指定xpath_kind,这里以CLASS_NAME为例
edge_driver.input_element_text(xpath_kind=By.CLASS_NAME, xpath='s_ipt',text="CLASS_NAME")
# 通过先抓取父元素,再指定父元素相对定位(在页面有弹窗时可以避免xpath绝对定位时导致的偏移,可以和xpath_kind复用,一般都是先找class_name抓到父元素,再在父元素下找对应的子元素)
father_element = edge_driver.get_element('//*[@id="form"]/span[1]')
edge_driver.input_element_text(father_element=father_element,xpath='./input',text="father_element")
# 通过批量抓取元素
elements = edge_driver.get_elements(xpath_kind=By.CLASS_NAME, xpath='s_ipt')
# 注意这里时不带element下标的函数,意味着需要提前抓取元素
edge_driver.input_text(elements[0],text="elements")
以上抓取方法可自由组合,在批量抓取的时候推荐先抓父元素。
批量抓取页面中信息
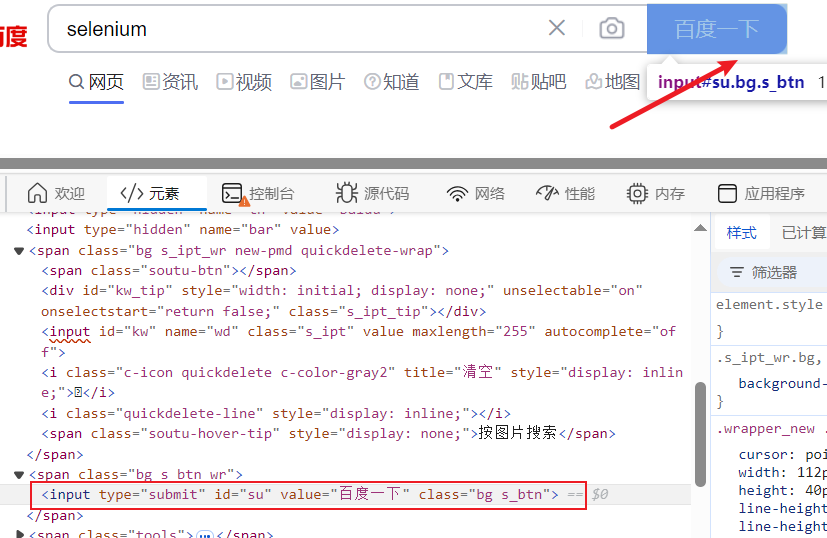
百度搜索按钮xpath如上图所示
edge_driver.click_element('//*[@id="su"]')
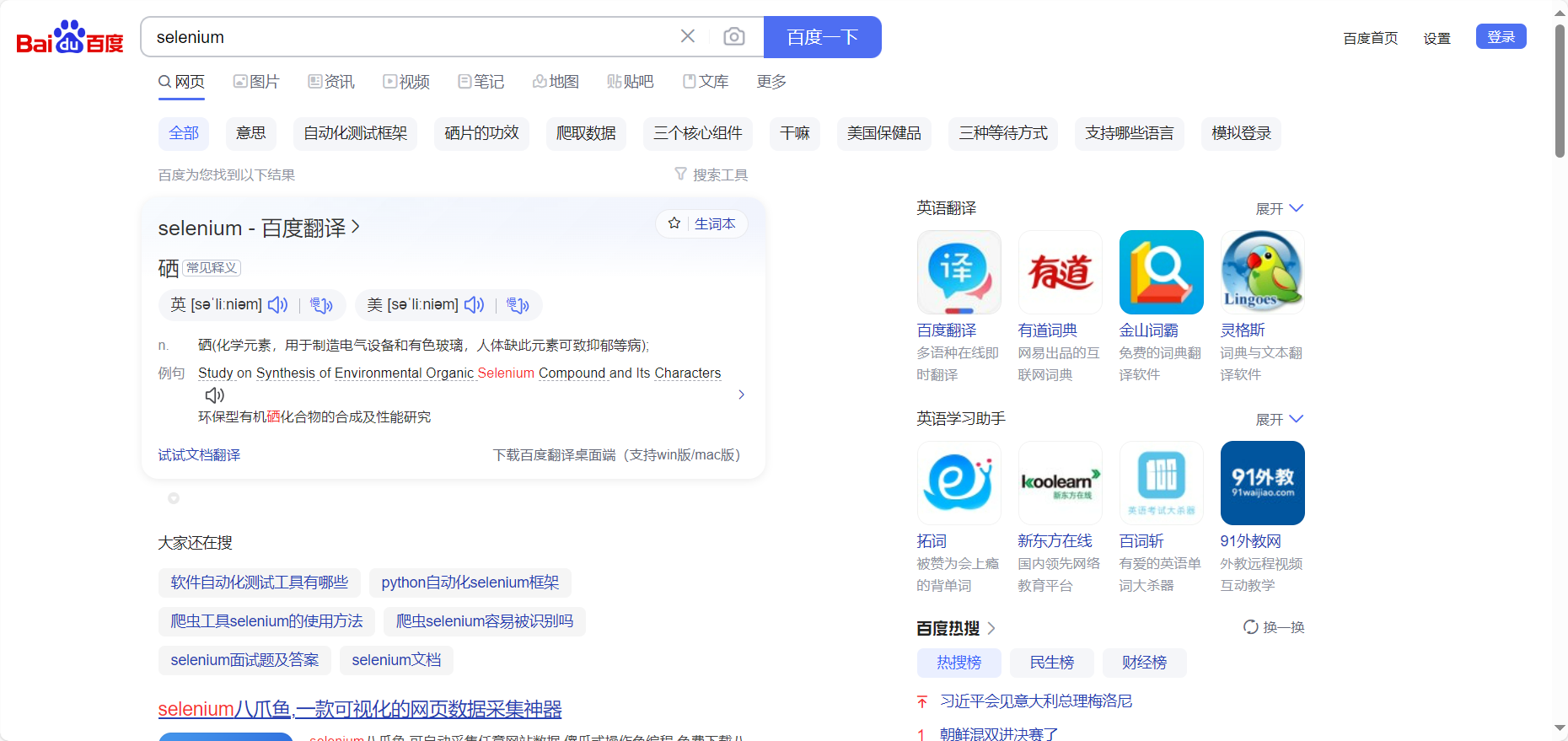
执行上面的代码可以获得如图所示的运行结果
# 初步提取信息
for info in info_list[3:]:
container = edge_driver.get_element(father_element=info,xpath_kind=By.CLASS_NAME,xpath='c-container',timeout=1)
# 这里可以打印一下看看结果,由于页面中结构不一样,有部分结构爬取不到出现false是正常的,这个时候可以过滤
# print(container)
if container:
# 同样可以打印一下看看结果
# print(edge_driver.get_text(container))
href_text = edge_driver.get_element_text(father_element=container,xpath='./div[1]/h3/a',timeout=1)
href = edge_driver.get_element_attribute(father_element=container,xpath='./div[1]/h3/a',attribute='href',timeout=1)
print(href_text,href)
False False
Selenium http://www.baidu.com/link?url=mSw9v0U3-70ku75zyu8qhoQ7z0gKEfDpZHGbBATYimDZNCypJ7xlNuQIuLAElMkf
selenium是什么意思_selenium的翻译_音标_读音_用法_例句... http://www.baidu.com/link?url=XWnVq8s_a3vvjgdhseeAqoDEA16JGNdsQjZa4k4Flhh2JstwdXQDyLzP4KdiqSG3
在上面的运行结果中可以看到由于页面中结构不一样,有部分结构爬取不到出现false是正常的,在初步时候可以打印看看效果
# 精细化爬取封装合并
selenium_info_list = []
for info in info_list:
container = edge_driver.get_element(father_element=info,xpath_kind=By.CLASS_NAME,xpath='c-container',timeout=1)
if container:
title = edge_driver.get_element_text(father_element=container,xpath='./div[1]/h3/a',timeout=1)
href = edge_driver.get_element_attribute(father_element=container,xpath='./div[1]/h3/a',attribute='href',timeout=1)
#过滤元素
if title or href:
selenium_info = {
'title':title,
'href':href
}
selenium_info_list.append(selenium_info)
print(selenium_info_list)
在确定好了爬取的元素后,进行精细化爬取封装合并,对爬取不到的元素进行过滤,具体问题具体分析,这里我简单给个例子直接过滤了
[{'title': 'Selenium', 'href': 'http://www.baidu.com/link?url=mSw9v0U3-70ku75zyu8qhoQ7z0gKEfDpZHGbBATYimDZNCypJ7xlNuQIuLAElMkf'}, {'title': 'selenium是什么意思_selenium的翻译_音标_读音_用法_例句...', 'href': 'http://www.baidu.com/link?url=XWnVq8s_a3vvjgdhseeAqoDEA16JGNdsQjZa4k4Flhh2JstwdXQDyLzP4KdiqSG3'}, {'title': 'Python爬虫基础之Selenium详解_python selenium-CSDN博客', 'href': 'http://www.baidu.com/link?url=_eqn5LDPPuCjccWFHnxPbBXiykn08xawnnDiv-KZqRIYe-IxOSp0zR_YI8o0EaTehtoG_XN0RXzndJPoSVBUD9sNaZQ56cVz2JOhqTsusKi'}, {'title': 'selenium详解(完整版)-CSDN博客', 'href': 'http://www.baidu.com/link?url=rivhW_6iVT5BmVKT4zoga4vpfNYF0aNg1NDBHkjk8rCmnVOKUYJVlZ217CAkMMI2ss1j5-vRpVU1Pbta0TKW3zdga2xncGA2Wbg2JNYo99m'}, {'title': '介绍| Selenium 中文文档', 'href': 'http://www.baidu.com/link?url=69ppUte2o9fACN0MNeaNzQuQvIodCxXNjMxtYxLlzZe6WBpylUzq5yNfFhMNvy-KAdC63klBTYngfph7QZLH1n2dLmFp9T3Q-3txuTJr9mUUEo7Jp2otzvPKEdaNR5Bb'}, {'title': '自动化测试工具:Selenium详解-CSDN博客', 'href': 'http://www.baidu.com/link?url=rivhW_6iVT5BmVKT4zogaGjj8vp3_liQqG4OVLnKjaVjladUedjTgAAXRRKoCFVMJbB-Zn8Hkwsh8K31vgOcFs1lzs9y8eiOndT309evF73'}]
总结
优点:简单易上手,对于新手或者是在机器学习获取数据方面遇到困难但不想在爬虫深入的同学及其友好,在爬取少量样本或网页没有反爬时十分好用——使用selenium爬取的时候,可以使用jupyter一步一步调试,直接通过开发者模式抓取网页中元素,对收集网页文本中的任务比如微博情感分析,简单地抓取图片等比较方便,拿来即用,调试的过程中直接就保存结果了,可以绕过一些普通的反爬。
缺点:速度较慢(远远没有js逆向来得快,js逆向是直接破解接口获取信息,是请求接口,selenium是抓取渲染页面元素,是请求dom),遇到boos直聘、天眼查这种需要查ip的时候一般爬个几百条就会被封(虽然说过个几个小时就能解封),
对比传统selenium与ltree:ltree其实原理和selenium差不多,都是用xpath抓元素,但是没有可视化,有时候一个bug查一下午发现是解码或者xpath找错了的问题,对于新手可能不太友好;而传统selenium,很多时候页面没有加载成功找不到元素就报错给你看,非常难绷,虽然有WebDriverWait函数,但是太难加了,不如封装为工具类,全部都是WebDriverWait,这样就能避免抓不到元素报错的问题。
PS:没有绝对好用的技术,要具体问题具体分析,爬取的任务量、网站的反爬措施、网站的数据结构等等都是应该考虑的问题,我一般都是selenium和ltree还有js逆向合起来用,先用selenium获取和注入即时cookie,然后直接解密接口,反正就是一句话——什么好用用什么。